Information Scratching Wikipedia The main benefit of automated internet scuffing is that it enables you to accumulate information a lot more rapidly, efficiently, and thoroughly than you 'd be able to complete manually. So the way of thinking of open data will certainly most undoubtedly affect the future of internet scuffing, developing even more difficulties for companies to overcome. Web data removal might end up being a luxury that only limited companies would be able to take pleasure in, because of greater costs. Big companies currently supply accessibility to their APIs for additional settlement, and extra companies will do so in the future. Websites owners are not resting on this and are making it harder. Yet internet site scraping is where we'll stay given that it's the most typical kind of it and some tech quarters normally define it as internet site scuffing. Public information is any info offered online that does not require any type of login details to access. In The Fan, the musician matched influencers' published Insta pictures with online video footage from the exact same place and minute. The contrast disclosed that behind the scenes of best Instagram Take a look at the site here grids are commonly dull and unimportant. After posting regarding it on social media sites, he was promptly prohibited based on copyright cases.
Is Information Scuffing Lawful?
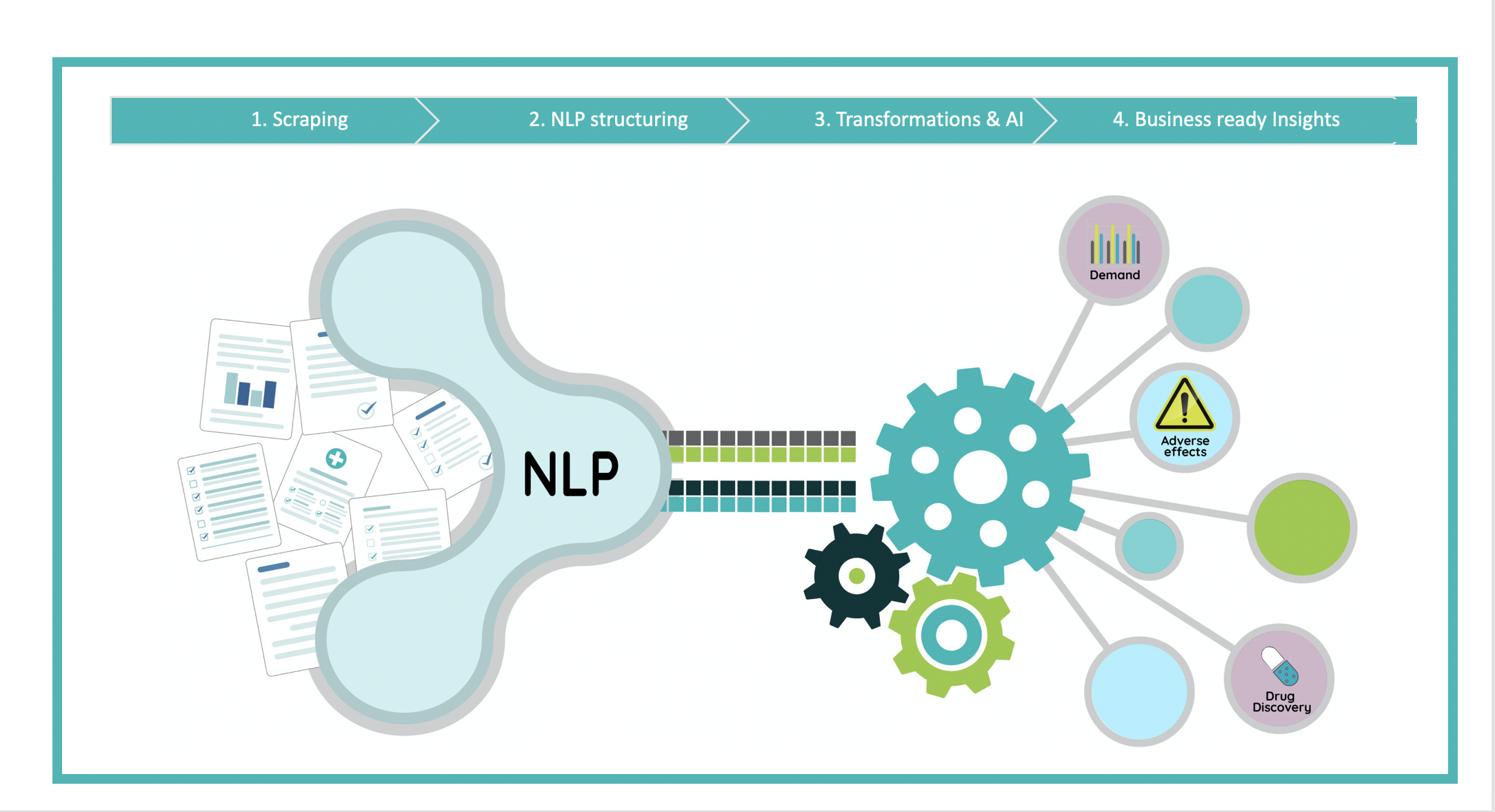
An innovative and durable application of this kind, improved a platform giving the governance and control required by a major venture-- e.g. Different information can originate from social media, blogs, information feeds, economic declarations, customer responses surveys, and other sources, offering companies with new point of views of their operations and markets. Alternative information streams have actually ended up being increasingly preferred for business to get valuable understandings right into customer habits, market trends, affordable evaluation, and future forecasts.California Begins World's Largest Dam Removal/River Restoration ... - Slashdot
California Begins World's Largest Dam Removal/River Restoration ....

Posted: Mon, 16 Oct 2023 03:34:00 GMT [source]
Data Center Proxies
The globe today is data-driven, and the future of information science is growing. Even when you represent the Earth's entire population, the average person is expected to generate 1.7 megabytes of data per second by the end of 2020, according to shadow supplier Domo. Therefore, the information removal room, as a whole, and web scratching, specifically, is anticipated to become a significantly complex domain, calling for ever before increasing degrees of specialized understanding and experience. Call us today for more information about how we can aid you browse anti-scraping procedures and remove internet data with confidence. In addition, firms must stand up robust data recognition abilities to ensure stringent data quality assurances that fulfill the precise specifications of the business. To stay in advance of the contour, it is essential to recognize and take action on the most up to date trends and forecasts in the ever-evolving space of web data removal and huge information.- This implies that while hiQ did not breach the criminal legislation, it breached an agreement (created by the approval of LinkedIn's Terms of Service).Also if your service has absolutely nothing to do with the internet, you'll be able to discover great deals of valuable and valuable details on the internet, which might assist you stay affordable.Data-driven choices powered by high quality data can fuel company development.Paired with information researcher's favorite, Jupyter Note pad, Python overshadows all the other languages used on GitHub in publicly open web scuffing jobs as of January 2023.Intense Insights to obtain workable eCommerce market knowledge.Therefore, the data and our searchings for do not represent the entire Information Science neighborhood.